Perception of vowels with missing formants
This research was completed in collaboration with Pamela Coulter, Terrance M. Nearey, and Michael Kiefte.
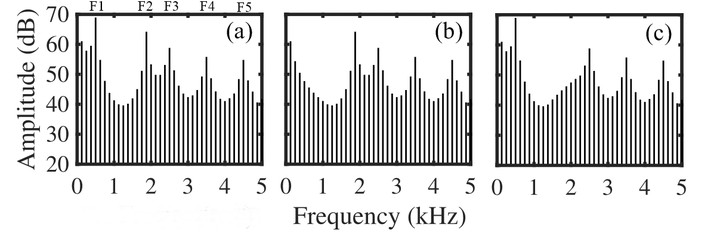
Look at image (a) above – that is called a spectrum. It shows frequency in Herz (Hz) on the x-axis and the amplitude (loudness) of the sound in decibels (dB) on the y-axis. This is a spectrum of a spoken vowel, showing you the loudness of different frequencies when it was produced. The peaks that you see on the speactrum are called formants. Researchers in the field of speech perception think these are the best cues to vowel identity, as different vowels tend to have loudness peaks at different frequencies. The first and the second formant are considered the most important to determining vowel identity.
However, a study conducted by Ito and associates showed that suppressing a formant – and you can see the effect of first formant suppression in image (b) and and the effect of second formant suppresion in image (c) above – barely had any effect on vowel categorization of synthesized Japanese vowels. Findings like these are in favor of a different approach to vowel perception, one which argues that the entire shape of the spectrum (not just the positions of the formant peaks) is used when a listener determines vowel identity.
Still, Japanese language only has five vowels and we thought that maybe suppressing a formant does not affect participant performance as much because there are so few options to choose from to begin with. We wanted to test this finding in English language because it has a much larger vowel inventory. We synthesized vowels and suppressed either their first or the second formant, just like Ito and his associates did. You can also have a listen to an example vowel below. The first formant value in this example synthesized vowel was 500 Hz and the value of the second formant was 2000 Hz.
Original synthesized vowel:
First formant suppressed:
Second formant suppressed:
The inspection of participant responses showed that – even when a formant is suppressed – changes in formant values affect participant categorizations. In other words, it looked like suppressing a formant does not alter participants’ perception as much as one would expect, somewhat matching the findings reported by Ito and associates. However, some closer quantitative analysis indicated that participants still don’t agree as much in their vowel identification when a formant (especially if it is the first formant) is suppressed.
One issue with the synthesized vowels Ito and associates and we used is that they do not change their formant values as they unfold. However, English features many diphthongs, that is, vowels that change their quality as they unfold. For example, the vowel in the word “snow” or the vowel in the word “out”. We thought that we needed more realistic stimuli to better assess the impact formant suppression has on vowel identification. We created new synthetic vowels and these featured formants with changing values over time. In fact, they were created to match the general production of vowels in Canadian English, taken from previous research conducted by Nearey and Assmann. Listen to the sounds below, they are examples of vowel / eɪ/, like in the word “paint”.
Original synthesized vowel:
First formant suppressed:
Second formant suppressed:
The results from the study using vowels with formant values changing over time showed that suppressing the first formant dramatically changes vowel perception in vowels that have a large change in the value of the first formant throughout its production. In English, these vowels are / ɪ, ɛ, oʊ, eɪ/. Not having access to formant information would really impede vowel perception of these vowels in everyday conversation. It seems that formants are still the most imporant and robust cues to vowel identity, even though some laboratory conditions can enable the listener to use other spectral cues as well. You can read more about this in our research article.